When digital systems unexpectedly fail, the consequences for businesses are huge. The cost of downtime can run to thousands of dollars per minute for large businesses, but the impact goes well beyond lost revenue.
In some cases, IT failures are just the tip of the iceberg; a falling stock price, reputational damage and customer dissatisfaction can all be potential side effects of a digital system failure. If those knock-on risks aren’t enough, they also point to inherent, unresolved vulnerabilities in an organization’s system.
Today’s distributed IT environments are increasingly complex, so it is easy to acknowledge why faults occur. What’s harder is understanding how to not only fix them but also how to reduce the chances of the unwanted scenario happening in the first place. More often than not, the many interdependencies created by the combination of cloud computing, microservices architectures and bare-metal infrastructure create multiple points of failure which are anything but predictable.
For that reason alone, introducing a level of chaos into the system could be the ideal way to get the gremlins out before the damage is unfixable.
Chaos engineering is a new approach to software development and testing designed to eliminate that unpredictability. By performing controlled experiments in a distributed environment, digital engineering teams can build confidence in the system’s ability to tolerate inevitable future failures.
How chaos engineering works
The process of chaos engineering involves stressing applications in testing or production environments by creating disruptive events in a controlled manner, such as server outages or API throttling. By then observing how the system responds, improvements can be made before those weaknesses affect real customers.
Chaos planning starts with identifying the target deployment for the experiment. This process makes it important to review the application architecture and infrastructure components fully first and define what we call steady state behavior. In other words, you need to understand what “normal” looks like before you start experimenting. You can then form a hypothesis about how the system will behave during the disruptive event.
These steps need to be replicated many times over in any given system to properly test its resiliency. Luckily, tools exist to help organizations implement and manage planned disruptions.
Chaos engineering with AWS Fault Injection Simulator
One such tool is AWS Fault Injection Simulator (FIS), a fully managed service for running fault injection experiments on AWS that helps improve the performance, observability and resiliency of applications.
Experiments need to be configured into templates for FIS that define the following:
- The IAM role needed to execute the experiment.
- What action you are performing.
- The services you are targeting with the experiment.
- The stop condition, to halt the experiment at any point in time.
All experiments are managed through the AWS Management Console. AWS is a region-specific service, so all the templates reside within specific regions. It should be noted that EC2 instance level chaos experiments require an SSM agent, but many other chaos tools need no agent installation.
Experiments can be stopped at any time and FIS can be integrated into an organization’s continuous delivery pipelines. Costs are charged pay-as-you-go, 0.10 USD/action-minutes.
How it works in practice
Let’s take an example of a web application hosted on EC2 instances with auto-scaling enabled, as seen in the diagram below. The application relies on a backend database – in this case we have AWS RDS with the multi-AZ enabled.
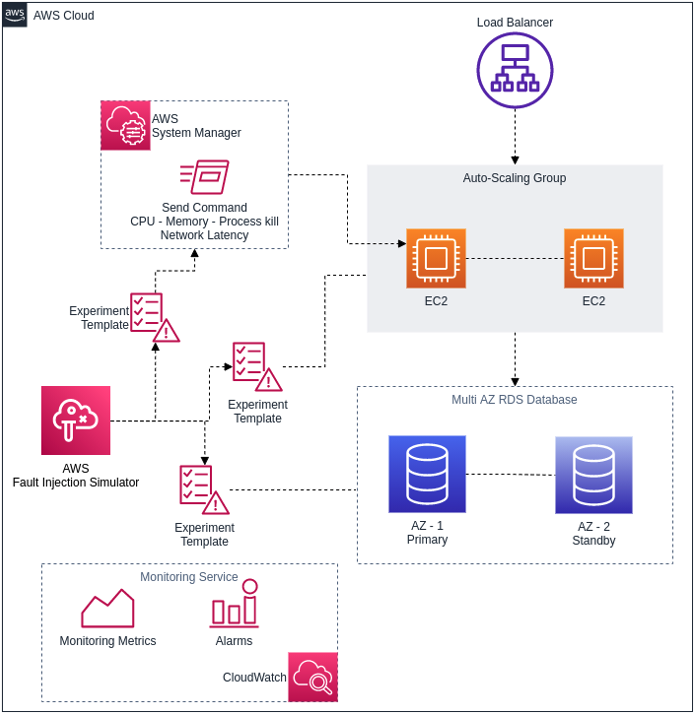
Three chaos experiments have been created using AWS FIS: one to check the resiliency of the RDS database, another to check to resiliency of EC2 instances and a third to execute CPU stress using the AWS Systems Manager Send command.
CloudWatch monitoring dashboards are ready to identify the application’s steady state and there is an alarm to trigger alerts if needed.
What are the benefits of FIS?
There are several advantages to FIS.
Firstly, FIS is fast and easy to use through AWS Management Console. Second, it provides insights by generating real failure conditions and provides visibility on how applications are performing on the AWS platform. As we noted above, it’s key function is to help teams improve application performance, resiliency and observability.
What are the alternatives?
While AWS FIS is a good fit for AWS-specific chaos engineering, companies looking for alternatives may want to consider ChaosToolKit, ToxiProxy, Gremlin, Chaos Monkey and LitmusChaos. All of these options are adept at unleashing chaos and providing the answers that you didn’t know you wanted.
Keep on experimenting…
Although chaos engineering sounds like a disruptive or uncontrolled exercise, it is actually the opposite. Chaos experiments require meticulous planning with the emphasis firmly on rooting out failures before they become outages. Far from lacking control, chaos testing is a closely coordinated process and the organization retains control of everything from the speed at which testing happens to what components are tested.
The bottom line is that chaos engineering teaches enterprises valuable lessons about the resiliency of their systems. And while chaos may not seem like a business optimization strategy, the plain truth of the matter is that a proactive attitude to reliability is something that a company can’t afford to ignore.
Happy experimenting!
To learn more about chaos engineering, from processes to tools, take a look at our whitepaper, What is Chaos Engineering? or contact us using the form below.