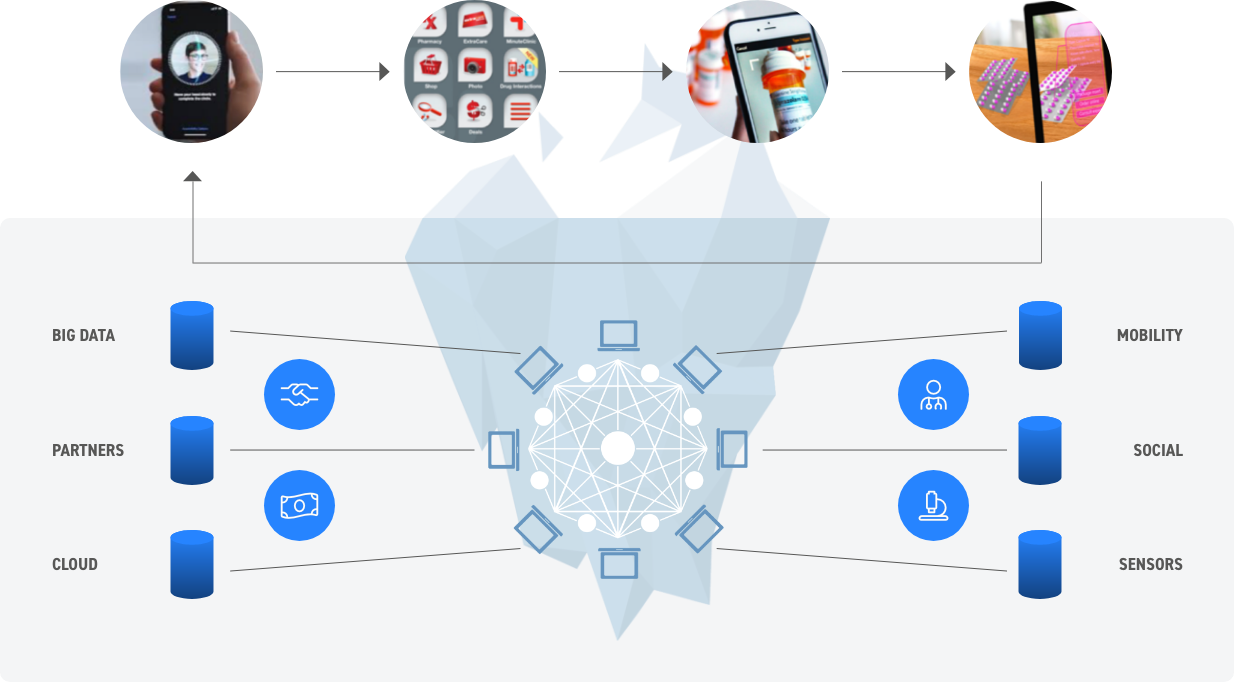
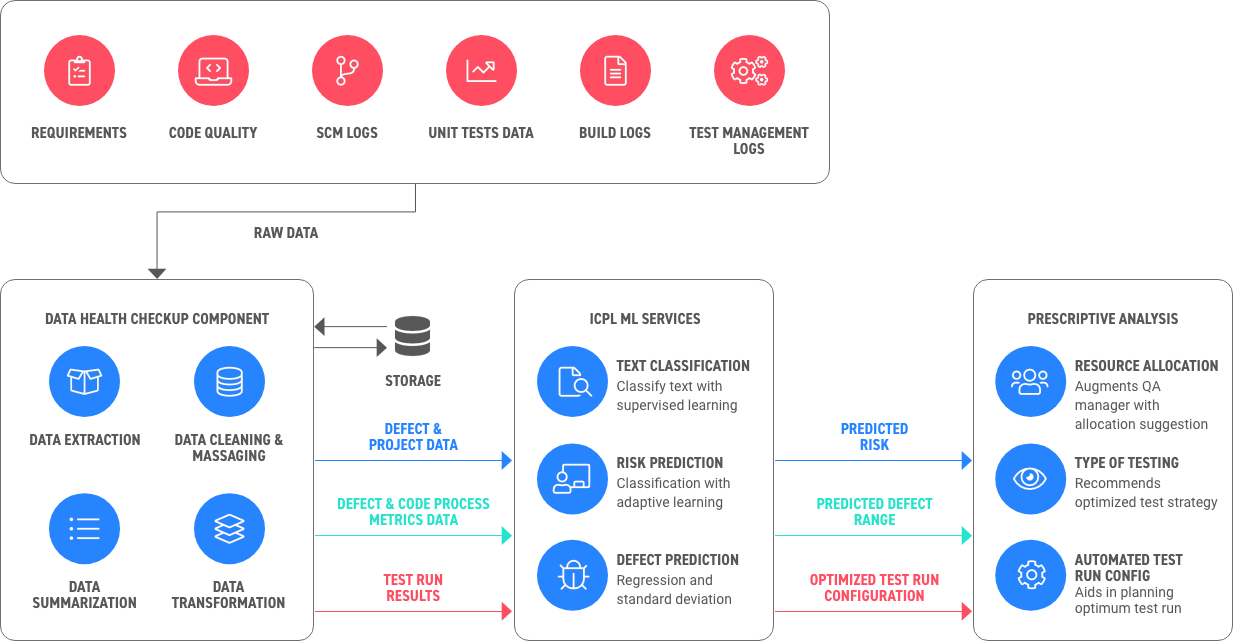
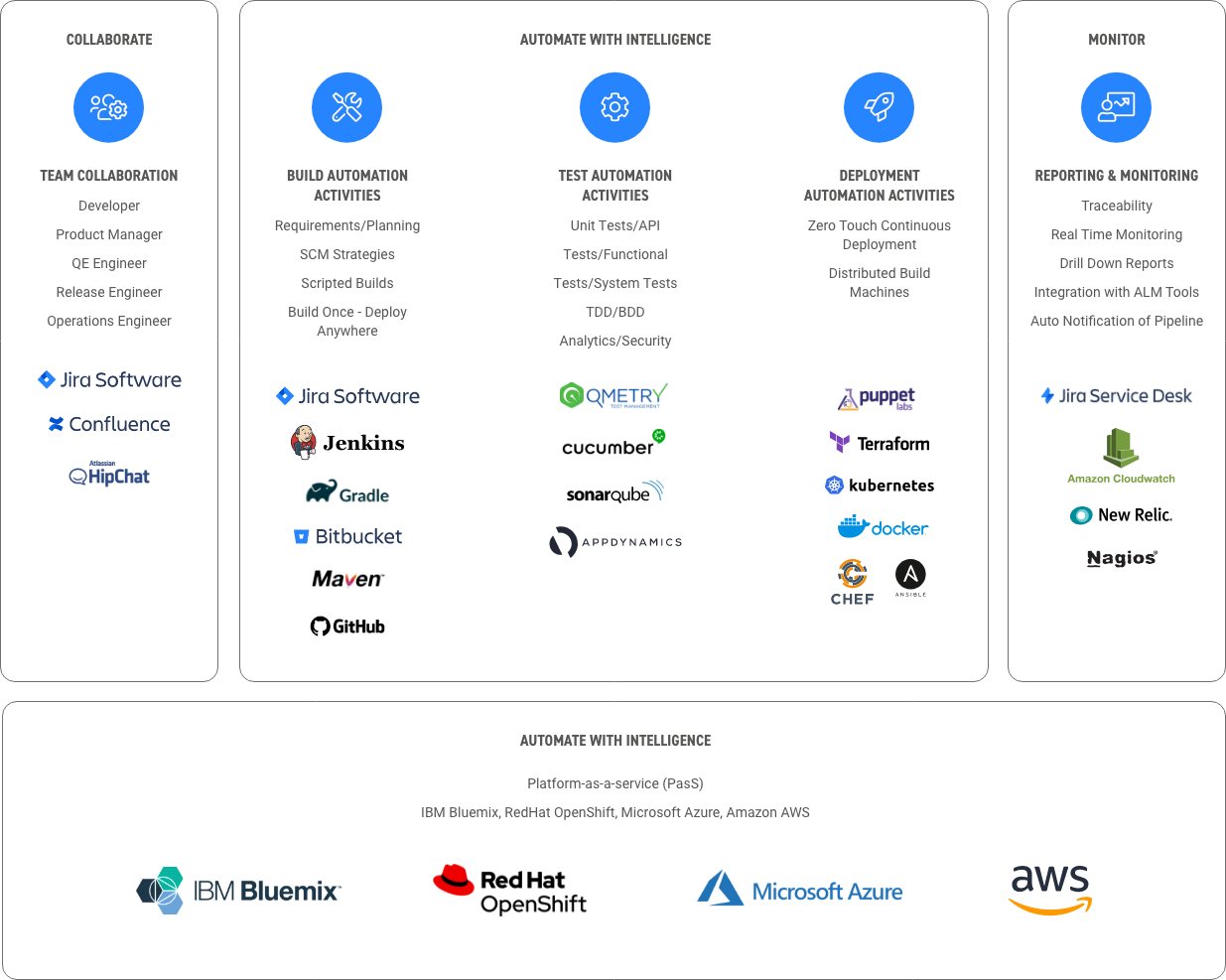
As much as we all dislike the term and the hype that goes with it, the reality is that there is substance to digital transformation – and we are living it, especially in the tech profession.
Services
- Quality Transformation: