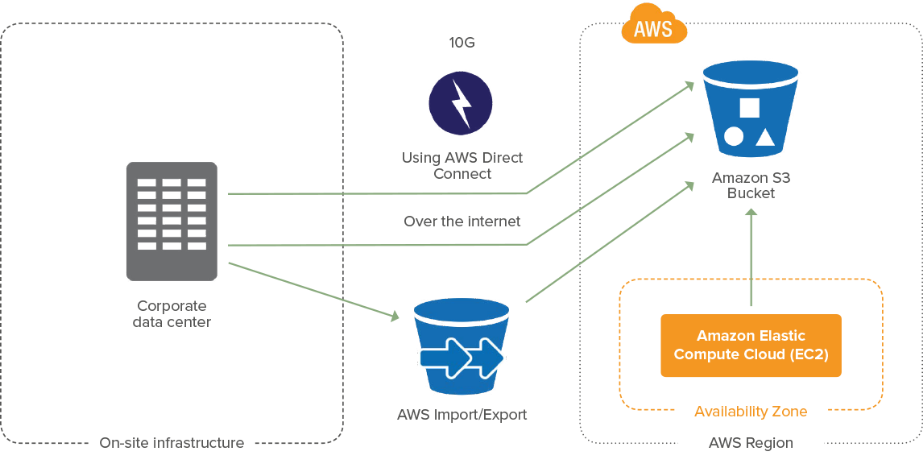
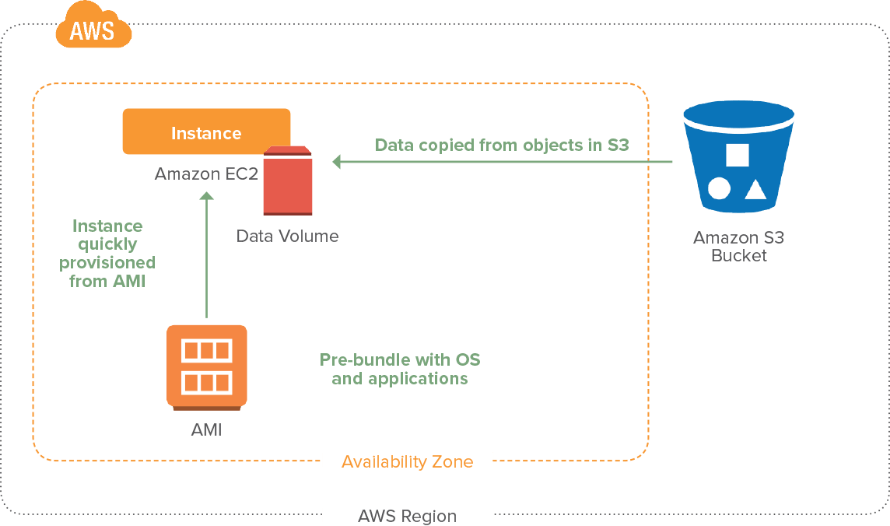
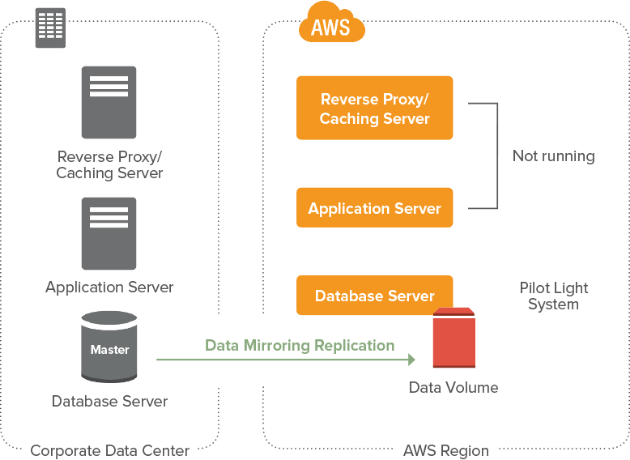
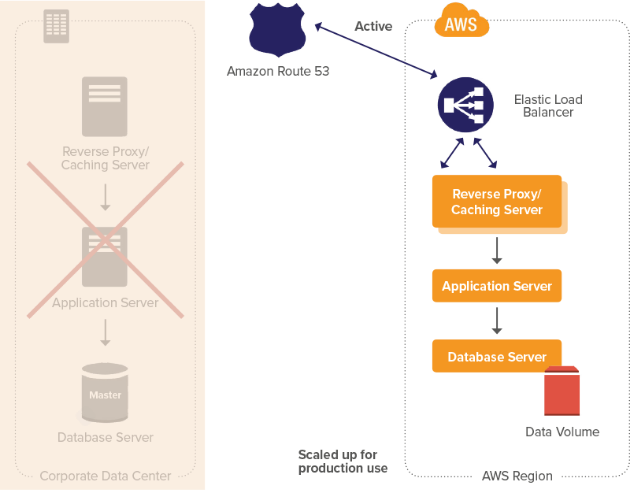
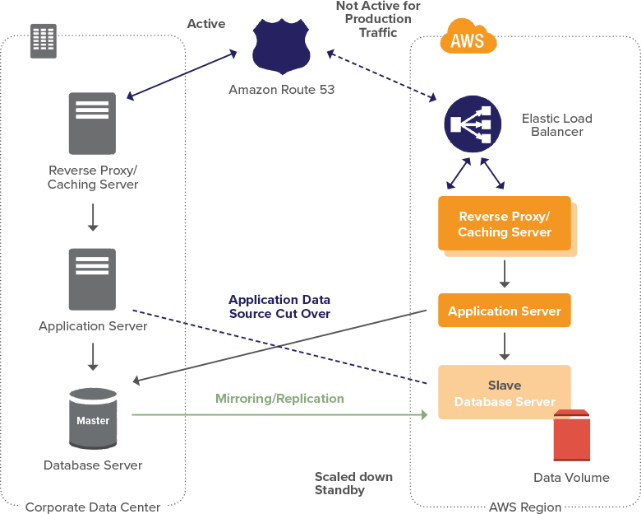
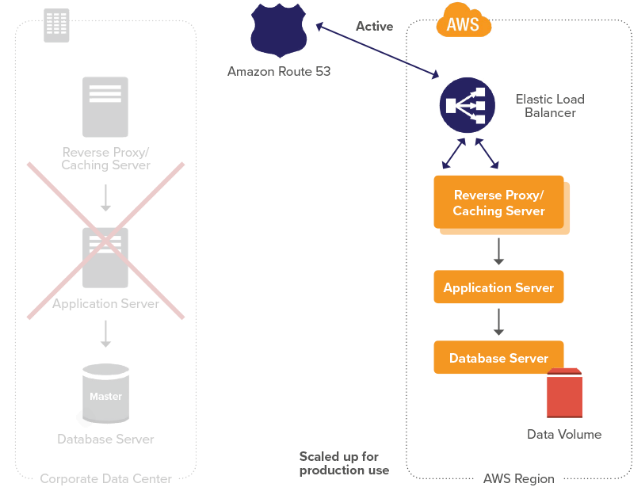
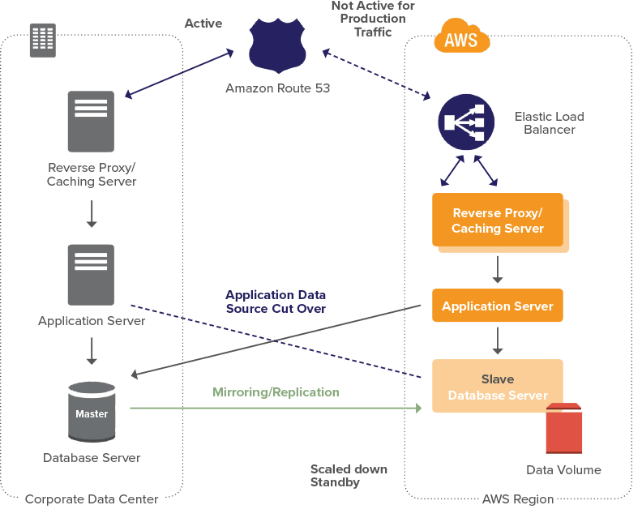
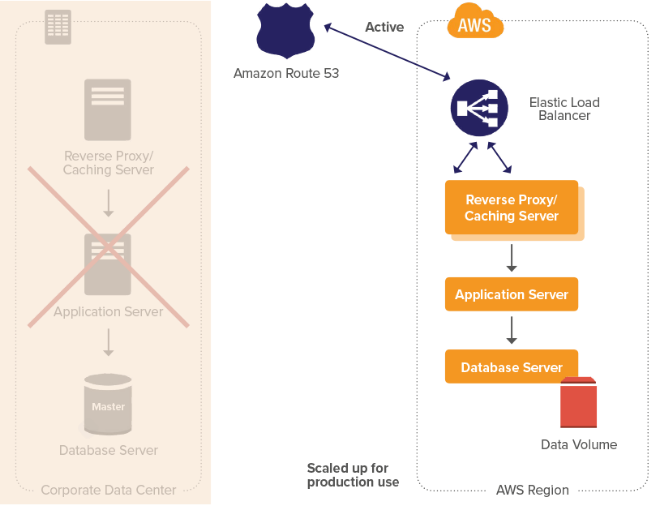
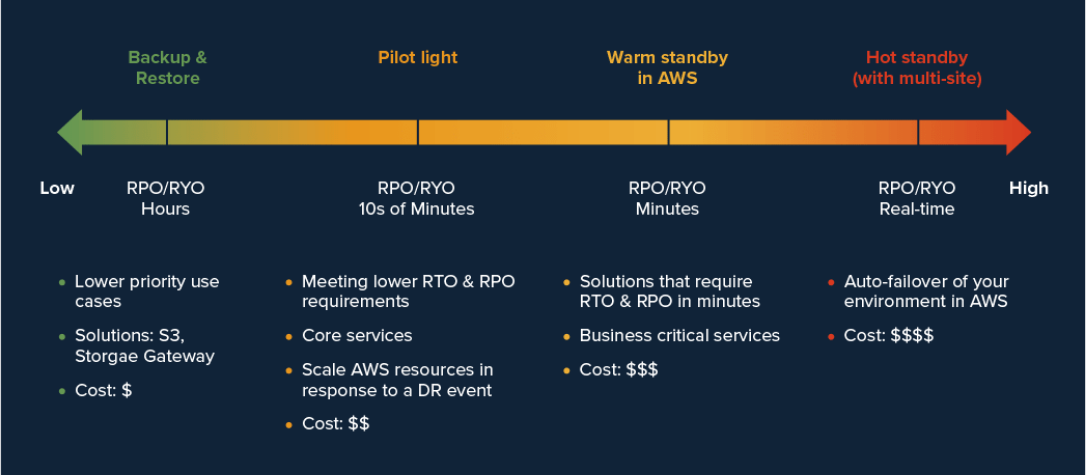
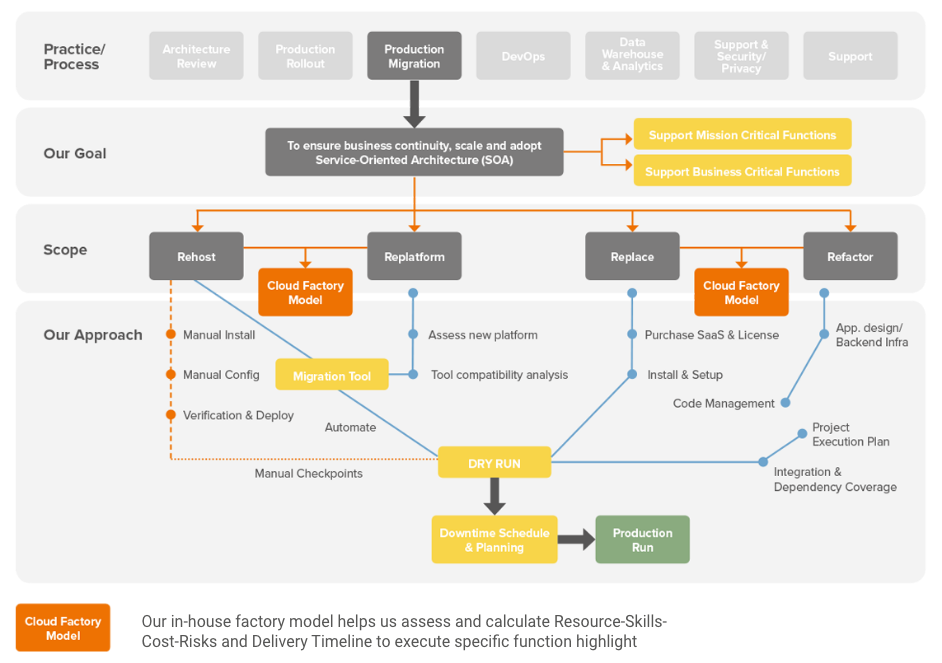
INTRODUCTION
Development & AWS Testing for Cloud Applications
This white paper guides project managers, developers, testers, systems architects, enterprises and anyone involved in software applications development activities.
It covers aspects of the AWS as a development platform, AWS cloud products and solutions, building cloud native applications, advantages of AWS, support, pipelines, automation, testing tools and techniques.